
seq2seq 手工实现及原理分析
背景问题
现实中,有一类问题是 输入输出不定长 的,比如
- 翻译,从中文到英文
- 文生图,一段话生成一个图片
- 摘要,总结一段话的信息
所以 seq2seq 就是为了解决这种 一串序列 生成 另外一串序列 问题的模型。
原理
seq2seq,sequence to sequence,也有另外一种叫法 encoder and decoder。他是一种上层模型架构,即是组合模型,他可以由不同的底层模型来实现。
我们可以先看原理图。
原理图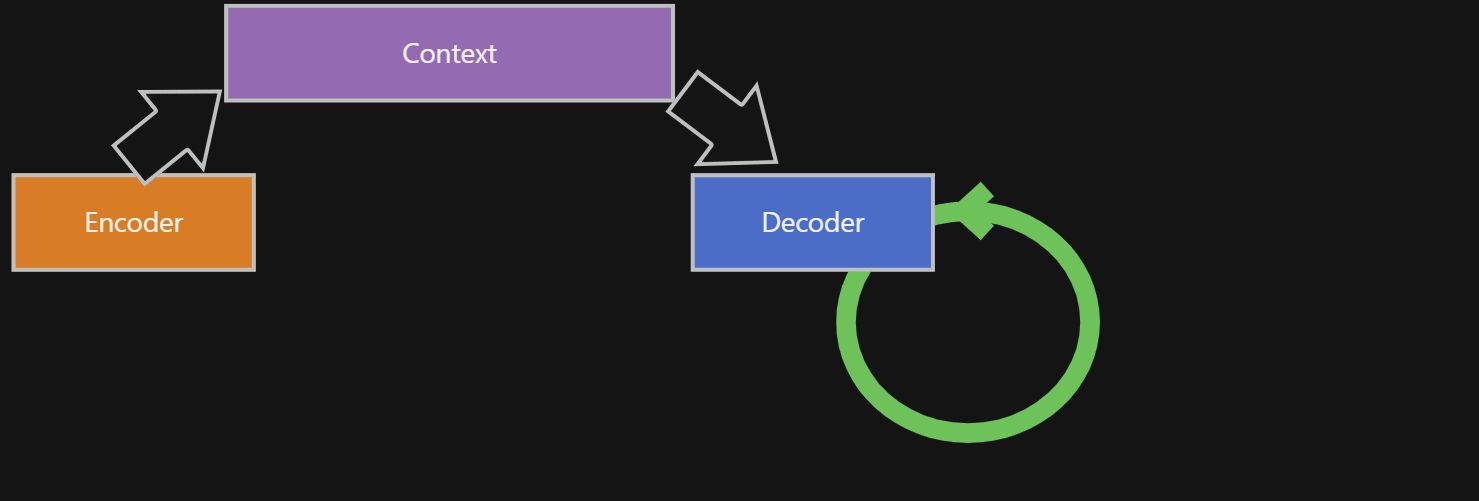
从原理图中可以知道,seq2seq 模型 有以下的特征:
- 模型都会有一个
Encoder,一个Decoder,和一个Context Encoder就是字面意思的 – 编码器,src_input经过Encoder处理,输出Context中- 同理,
Decoder就是解码器,tgt_input和Context经过Decoder处理, 输出tgt_output Encoder和Decoder都必须能够识别Contextsrc: source, tgt: target
🔥 Context 的组成是非常重要的,他是 Encoder 和 Decoder 是能够识别的一个介质,是链接两者的桥梁。这种介质可以是 _隐状态_,可以是 _注意力的加权计算值_,等等,这些都由底层的模型来决定的。
就好比国际贸易中,我们想买澳大利亚铁矿。 美元是硬通货,中间介质,ZG 和 土澳 都认美元,所以 ZG encoder 先把 RMB 转成 Dollar,给到土澳 decoder,土澳再换回自己的 澳元。
🔥 不定长,输入值(比如,长度是 8)在 Encoder 都转换成统一的 Context(比如,128 X 512 的 2 层神经网络),同时 输出值的长度(比如,长度是 10 ) 由 Decoder 和 Context 来决定,已经与输入值无关了。
同时,seq2seq 仅仅是上层架构,底层实现的模型是啥都可以视情况而定。比如,底层可以是 RNN,可以是 LSTM,也可以是 GRU, 也可以是 Transformer。本文例子中使用 RNN 来实现。
例子 – 翻译
下面是手工实现一个基于
RNN的seq2seq模型。可运行的 ipynb 文件的链接。
任务目标
例子的目标,从有限的翻译资料中,训练出翻译的逻辑,实现从英文翻译成法文。
分析任务
这里先不讨论字符的处理流程(清洗字符,过滤特殊字符等),所有的流程简单化,仅仅是验证模型的使用。
- 翻译是一个“分类”任务
- 这个是一个不定长的输入和输出的,所以使用
seq2seq的模型 - 同时输入和输出是有时间序列的,所以底层模型使用带有记忆能力的模型,我们使用
RNN
❓ 为什么是一份分类的任务?
这其实是 word2index 的过程,每个 word 就是一个分类。举例:比如 输入的是英文,英文中的一共有 4000 个单词,那么输入的分类就是 4000 ;输出的是法文,法文中的一共有 2000 个单词,那么输出的分类就是 2000。
代码结构
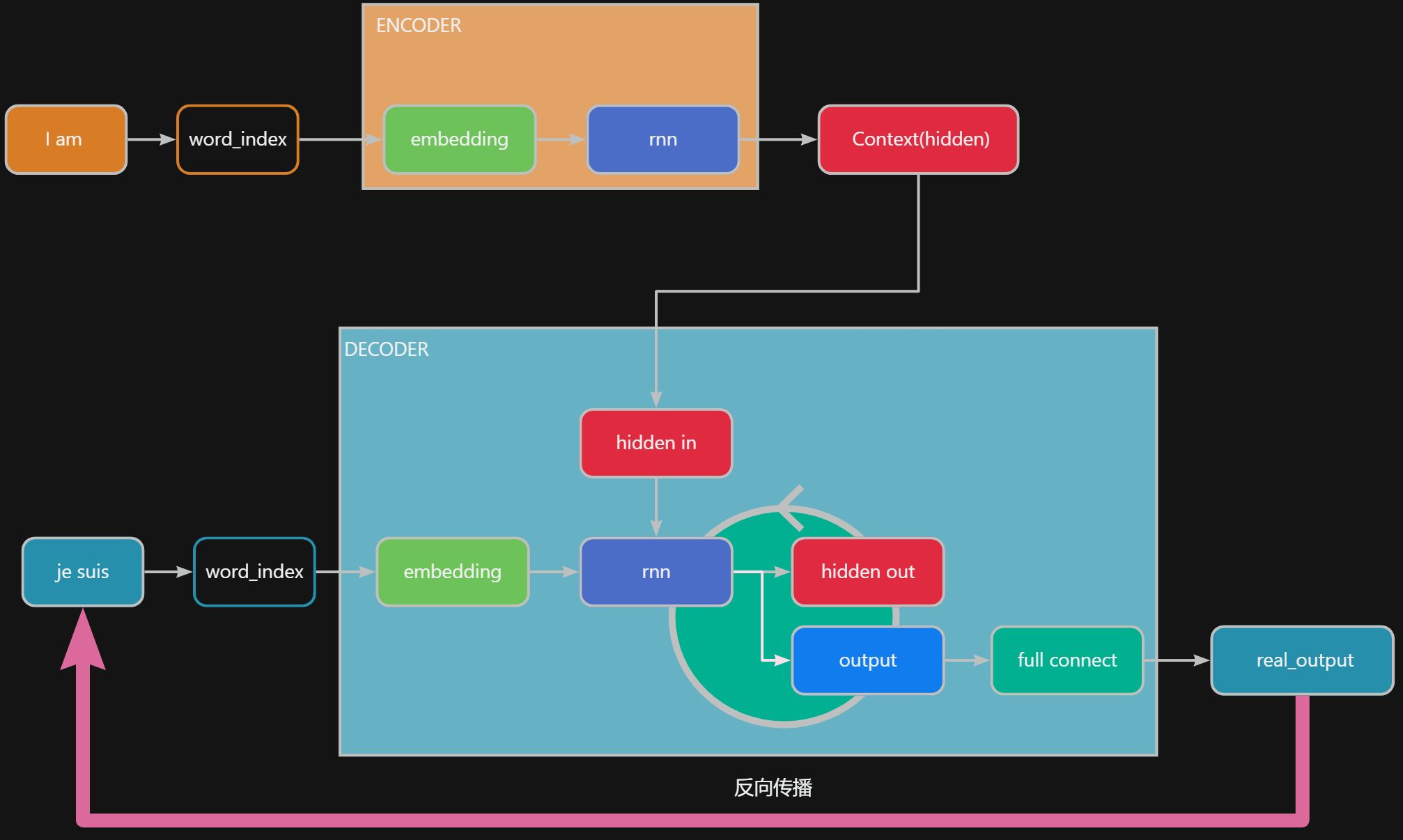
上图是 数据在 seq2seq 流动中串起不同组件的过程。
组件说明:
word_index,就是把单词转换成indexembedding,就要把离散的index转换成可以计算的连续的embedding,适合模型的计算word_index和embedding正常情况是 输入和输出都不能共用的encoder里面有embedding,rnnrnn输入src, 输出hidden隐状态,即Context
decoder里面有embedding,rnn,full_connectrnn循环叠加输入tgt_input和Context, 输出new hidden,tgt_outputfull_connect负责把tgt_output生成真正的real_tgt_ouput了解他们的具体职责后再去看他们的代码就清晰多了
代码片段分析
1 | # Define the Encoder RNN |
上面是 encoder 的代码,作用就是:
src_input转成embeddingrnn把embedding转成hidden,即Context
1 | # Define the Decoder RNN |
上面是 dncoder 的代码,与 encoder 比较多了一个 full connect 使用
tgt_input转成embeddingrnn把embedding转成hidden和outputfull conect再把output转成output_feature
1 | # Define the Seq2Seq model |
上面的代码是 seq2seq 模型的定义。
训练过程
可以检查数据在这个模型中流动如下:
- [1] 里面包含了一个
encoder和decoder - [2]
forword时,encoder转换src_input成hidden - [3] 开始
decoder循环,最大长度是max_len。初始化即是:decoder_input = “<sos> index“,decoder_hidden = encoder_hidden - [4]
decoder输出是output_index+new_hidden - [5]
decoder_input+= output_index,decoder_hidden += new_hidden叠加后再走步骤 [3] 循环
💡 teacher_forcing 是什么?
就是训练的时候,有一定的概率输出是 真实值 而不是 _预测值_。就能是模型更加快的收敛,加速模型的学习。但是过于依赖 _真实值_,就会导致泛化能力差。teacher_forcing_ratio 就可以调整阈值。
推理过程
1 | input_seq = torch.tensor(indices, dtype=torch.long).unsqueeze(0) # (1, seq_len) |
推理过程 和 _训练过程_,具体原理一致。 有以下的差异点需要注意:
- 如何定义开始输出的标志
- 如何定义结束输出的标志
- 如何定义不认识字符的标志
代码分析:
- [1] 单独使用
seq2seq's encoder,且 一次性 生成encoder hidden - [2]
decoder_input初始化,以 ‘‘ 开头,标志开始输出 - [3]
decoder开始循环- [4] 单独使用
seq2seq's decoder, 输出ouput和new_hidden - [5] 碰到不认识的分类,就使用 ‘
‘取代 - [6] 如果遇到 ‘
‘ 字符就直接结束循环 - 回到 [3] 继续循环
- [4] 单独使用
结果
1 | # 训练结果 |
总结
seq2seq是一种上层模型架构,应对输入和输出不定长的场景seq2seq底层可以由不同的模型构成seq2seq的Context是保存了上下文信息,是encoder和decoder都必须能识别的格式


